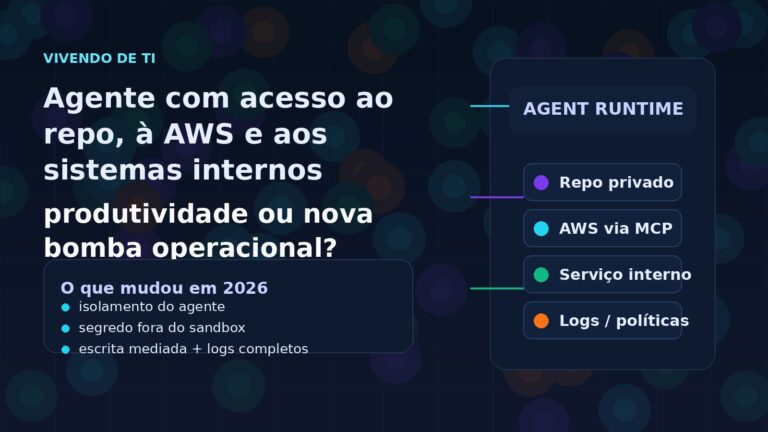
Agente com acesso ao repo, à AWS e aos sistemas internos: produtividade ou nova bomba operacional?
TL;DR: agente de IA com acesso real ao repositório, à cloud e a sistemas internos pode acelerar tarefa chata de verdade. O problema é que, quando esse agente ganha caminho livre demais, ele também vira um ponto novo de vazamento, escrita indevida e bagunça difícil de auditar. O movimento mais sério de 2026 não é “dar mais autonomia” por si só. É cercar essa autonomia com isolamento, permissões estreitas, escrita mediada e log decente.
Tem muita equipe ainda olhando para agente de código como se fosse só um Copilot mais corajoso. Já não é mais isso.
O que começou como sugestão de código e automação leve agora está encostando em coisa sensível de verdade: repositório privado, credencial de cloud, banco interno, ticketing, documentação corporativa e fluxo de CI/CD. A pergunta útil deixou de ser “o agente consegue fazer?” e virou outra: o que exatamente esse agente pode tocar sem virar problema depois?
O mercado começou a tratar o agente como parte da operação, não como brinquedo
Nos anúncios mais recentes, o padrão ficou bem claro. A conversa não gira mais em torno de prompt bonitinho. Gira em torno de execução governada.
A AWS colocou em GA o AWS MCP Server, empurrando a ideia de que o agente pode acessar serviços reais da conta sem ficar inventando comando de CLI ou trabalhando com documentação desatualizada. O ponto importante não é só a integração. É o jeito: ferramenta pequena, autenticação via IAM, observabilidade própria e run_script em sandbox sem acesso de rede externo. Isso já mostra uma mudança de mentalidade. Ninguém sério quer entregar a chave da conta para um agente e torcer.
O lado Anthropic + Cloudflare foi pela mesma direção. Entraram em cena self-hosted sandboxes, MCP tunnels e proxies de saída para deixar o “cérebro” do agente separado das “mãos” que executam coisa sensível dentro do perímetro da empresa. Em português claro: usar modelo hospedado fora e, ao mesmo tempo, manter execução, acesso privado e política de rede do lado de dentro.
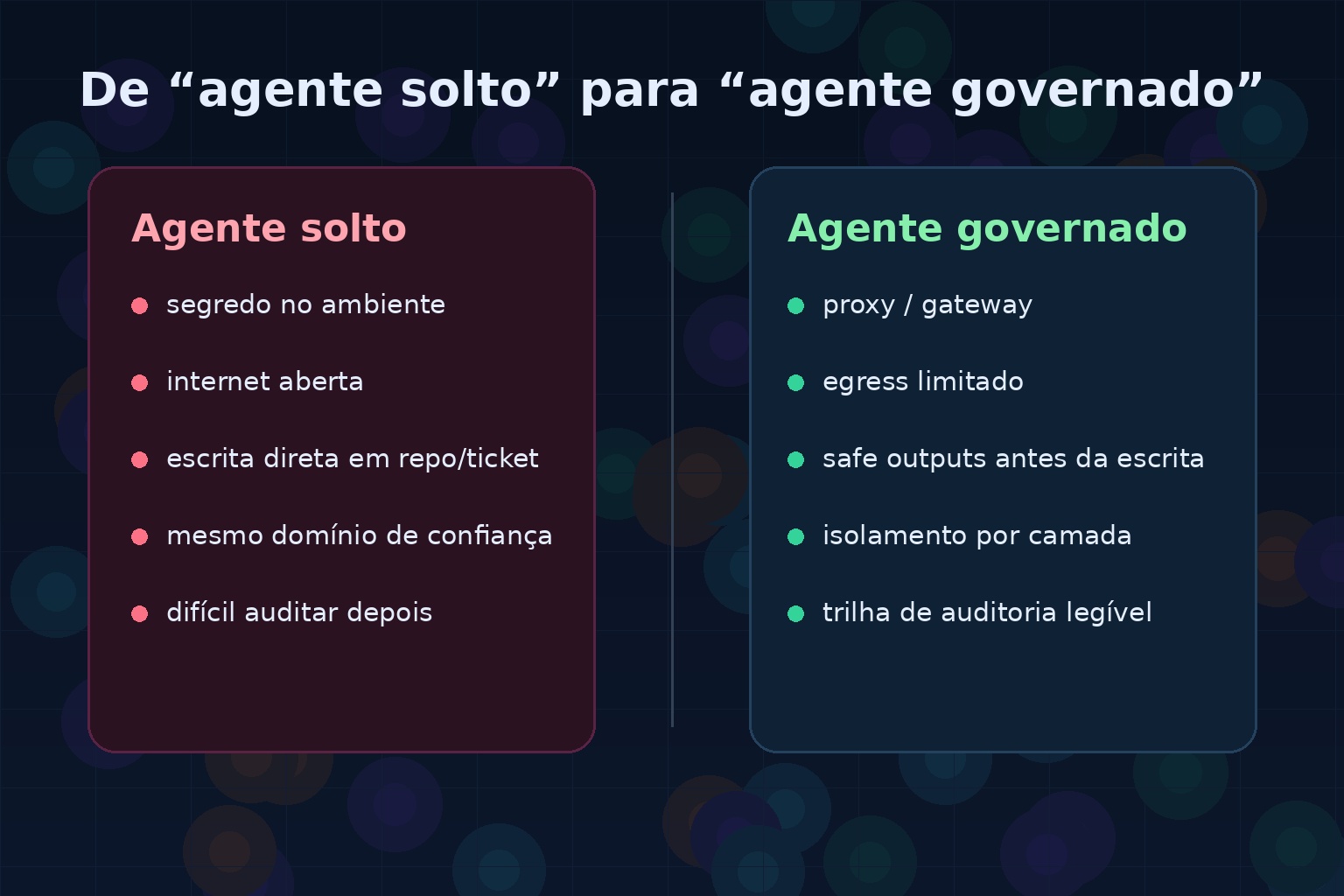
O GitHub também foi por esse caminho ao detalhar a arquitetura de segurança dos Agentic Workflows. A parte mais interessante ali não é marketing. É o desenho: agente isolado, sem acesso direto a segredo, escrita passando por uma camada de safe outputs, restrição de rede e log em cada fronteira importante.
Quando três linhas diferentes do mercado começam a bater na mesma tecla, vale ouvir. O recado é simples: agente útil em produção não pode ser tratado como script esperto rodando solto no mesmo domínio de confiança do resto.
O risco não é teórico quando extensão, repo e credencial ficam perto demais
Essa preocupação não nasceu do nada. O próprio GitHub divulgou nesta semana a investigação de um acesso indevido a repositórios internos envolvendo uma extensão maliciosa de VS Code em um device de funcionário. Segundo a empresa, a atividade exfiltrou repositórios internos e forçou rotação rápida de segredos críticos.
Não foi um caso de “agente rebelde”. Mas o pano de fundo é o mesmo: ferramenta com acesso demais, rodando perto demais de material sensível, aumenta raio de explosão quando alguma peça da cadeia dá errado.
É por isso que a discussão sobre agentes ficou mais séria tão rápido. Se o fluxo inclui repo privado, token, shell, browser, túnel para serviço interno e capacidade de escrever em sistema real, não adianta tratar governança como detalhe para depois. O “depois” costuma chegar em forma de incidente, vazamento ou automação escrevendo onde não devia.
Quais guardrails realmente importam
A parte boa é que o mercado já está mostrando um conjunto de controles que faz sentido na prática. Não é bala de prata, mas já dá para separar time que está brincando de time que está montando operação decente.
1) Segredo fora do alcance do agente
Esse é o ponto mais importante.
O desenho mais saudável é aquele em que o agente usa uma capacidade sem necessariamente enxergar o segredo bruto. Proxy autenticado, gateway para MCP, header injection fora do sandbox e credencial só na camada confiável são muito melhores do que token aberto no ambiente do agente.
Se o modelo for prompt-injetado, fizer tool call errada ou simplesmente se comportar mal, o estrago cai bastante quando ele não consegue ler segredo diretamente.
2) Permissão estreita e separação entre leitura e escrita
Agente que pode consultar documentação, ler estado do repo ou inspecionar cloud não precisa automaticamente ganhar permissão de mutação ampla.
A AWS já está empurrando isso com políticas IAM finas e telemetria separada. O GitHub também reforça a ideia de workflows em estágios, com escrita mediada depois da execução do agente. É o tipo de detalhe que parece burocracia até o dia em que impede comentário em massa, PR lixo ou alteração indevida em recurso real.
3) Escrita mediada, não escrita direta
Esse ponto merece mais atenção do que costuma receber.
Quando o agente escreve direto em issue, PR, ticket ou sistema interno, qualquer erro vira efeito colateral público ou operacional. A alternativa melhor é fazer o agente propor, bufferizar e só depois passar por filtro: tipo de ação permitido, quantidade máxima, sanitização de conteúdo, validação humana quando necessário.
Isso é especialmente importante para times que querem usar agente em:
- abertura de PR
- comentário em ticket
- atualização de documentação
- ações em cloud
- automação interna com múltiplos sistemas
4) Log que permita reconstruir o caminho inteiro
“Tem log” não basta. O log precisa mostrar pelo menos:
- que ferramenta o agente chamou
- para qual destino ele tentou sair
- que artefato ele leu ou escreveu
- que política bloqueou ou permitiu a ação
- em que etapa o comportamento estranho apareceu
Sem isso, toda investigação vira caça ao fantasma. E time de TI já tem fantasma suficiente sem precisar inventar mais um.

Onde isso acelera de verdade — e onde costuma dar ruim
O lado bom existe, e ele é bem concreto.
Agente com acesso governado pode ajudar bastante em tarefas como:
- investigar estado de infraestrutura sem caçar documentação velha
- cruzar logs, tickets e configuração para triagem inicial
- abrir PR de ajuste pequeno com contexto do repo
- consultar sistemas internos sem fazer alguém copiar e colar tudo na mão
- executar rotina repetitiva com trilha de auditoria melhor do que macro improvisada
O problema começa quando a empresa quer pular etapas e entregar autonomia antes de desenhar limite.
Normalmente dá ruim em alguns padrões bem previsíveis:
- agente com shell + segredo + internet aberta
- acesso ao repo privado no mesmo ambiente que extensões, plugins ou ferramentas pouco auditadas
- escrita direta em produção ou em sistema corporativo sem estágio intermediário
- túnel para serviço interno aberto sem política por destino
- “vamos liberar primeiro e pensar na governança depois”
Esse último é clássico. E costuma sair caro.
O rollout minimamente saudável para um time real
Se eu estivesse colocando isso para rodar num time de produto, plataforma ou infra hoje, eu não começaria com “agente totalmente autônomo”. Eu começaria com algo bem menos cinematográfico e muito mais útil.
Primeiro, leitura forte e escrita fraca. O agente pode ler bastante contexto e sugerir muita coisa, mas mutação real entra limitada.
Depois, escopo estreito. Um fluxo por vez. Exemplo: triagem de issue, geração de PR pequeno, consulta de documentação interna ou leitura de estado de cloud. Misturar tudo cedo demais é convite para perder noção de causa e efeito.
Em seguida, política de egress e identidade. Quais hosts ele pode acessar? Quais APIs? Quais ferramentas? O que fica em proxy? O que fica em gateway? O que nunca entra no alcance do agente?
Por fim, trilha de auditoria que alguém de infra, segurança ou plataforma consiga ler sem fazer arqueologia.
Parece menos empolgante do que vender “dev autônomo no Slack resolvendo tudo”. Só que é esse desenho mais chato que aumenta a chance de a automação continuar viva depois do primeiro susto.
No fundo, 2026 está deixando uma lição bem direta para quem trabalha com dev tools, plataforma e segurança: quanto mais capaz fica o agente, menos aceitável fica tratá-lo como extensão inocente de produtividade.
Ele pode render muito. Mas, se tocar repo, cloud e sistema interno ao mesmo tempo, já entrou no território da operação real. E operação real cobra isolamento, governança e rastreabilidade — não como luxo, mas como preço de entrada.
Fontes
-
AWS Blog — The AWS MCP Server is now generally available
https://aws.amazon.com/blogs/aws/the-aws-mcp-server-is-now-generally-available/ -
InfoQ — Anthropic Introduces MCP Tunnels for Private Agent Access to Internal Systems
https://www.infoq.com/news/2026/05/claude-mcp-tunnels/ -
Cloudflare Blog — Announcing Claude Managed Agents on Cloudflare
https://blog.cloudflare.com/claude-managed-agents/ -
GitHub Blog — Under the hood: Security architecture of GitHub Agentic Workflows
https://github.blog/ai-and-ml/generative-ai/under-the-hood-security-architecture-of-github-agentic-workflows/ -
GitHub Blog — Investigating unauthorized access to GitHub-owned repositories
https://github.blog/security/investigating-unauthorized-access-to-githubs-internal-repositories/


